Pinpoint valuable unstructured text data with precision
using your unique business and domain-specific language
Leverage your own expertise to access precisely tailored data for AI, LLMs, ML, RPA, BI, Research, Talent, and BAU applications.

Curate, measure, filter, match, label, and route text automatically with prioritized Weighted Topic Scoring criteria you define and metadata we generate.
Keep the human in command with patented matching technology you control
“DataScava perfectly complements existing approaches to unlocking the value of unstructured text data – by helping companies to model higher-level intents and purposes behind the labeling and classification of data – by defining the abstract topics and themes that represent their own business and subject matter expertise – and by applying both to big data sets real-time.”
-Scott Spangler, Chief Data Scientist, IBM Distinguished Engineer, Author “Mining the Talk: Unlocking the Business Value in Unstructured Information”
Read More
How It Works
Our three proprietary methods help you focus on the information you care about and adapt to evolving industries and user needs.
Tailored Topics Taxonomies
(TTT)
TTT models features and topics within heterogeneous text using specialized taxonomies you can select, create, edit, or import to define business language and domain expertise, allowing for the highly customized vocabulary and logic necessary for complex document processing. TTT incorporates customizable taxonomies, allowing users to define and control how information is categorized within their specific domain. This is beneficial for users who require highly tailored insights.
Read More
Domain-Specific Language Processing
(DSLP)
DSLP emphasizes processing language within specific domains. The system is tailored to identify terminologies and jargon of a particular industry subject area and of your organization, working as an alternative or adjunct to traditional NLP and incorporating domain-specific knowledge into the language processing pipeline. DSLP indexes text at the file level to generate weighted topic scores and other metadata, surfacing relevant textual files from large datasets.
Read More
Weighted Topic Scoring
(WTS)
WTS accurately measures and matches topics according to user-defined score thresholds and labels documents into appropriate cohesive categories using heuristic techniques tailored to a specific business purpose, enabling a true human-machine partnership in an ever-changing environment. WTS goes beyond basic frequency-based measures by weighting topics based on their importance and relevance, allowing for a more refined prioritization of topics.
Read More
Unlock Your Data

Curate quality training data sets to unleash AI and optimize Machine Learning models; identify key BI or Research data; filter emails, inquiries, or tickets for service desks or RPA; mine chats, notes, news, reports, contracts, or transcripts; identify skills for People Analytics or Talent Acquisition; and more.
Our practical, easy-to-use toolset lets you capture the business ontologies that provide the critical bridge between unstructured data analysis using standard data science techniques and the human expertise that gives your business its competitive edge.
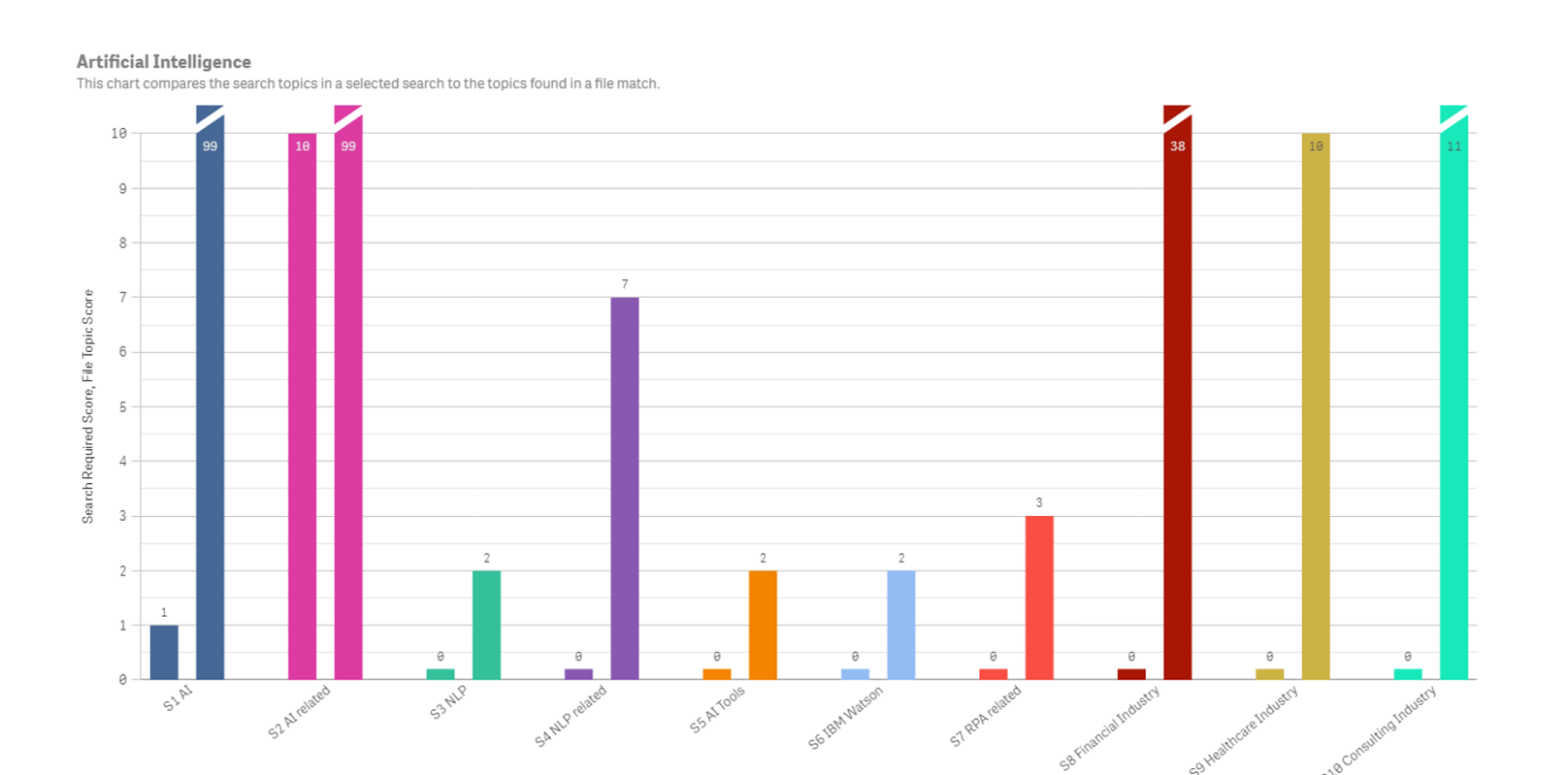
A Weighted Topic Scoring File Match
DataScava enables a more data-centric approach to business applications, with topic models that reflect the primary areas of focus, flexible topic scoring to encode your organization’s priorities, and customized text processing that mirrors the way people actually communicate in the industry.
Our sophisticated algorithm assigns weights to topics based on their importance and relevance within the domain. This advanced scoring function you control based on your interests, priorities, and intents enables you to focus on the most critical topics and discard noise, leading to better insights.
How It’s Different
DataScava ensures cross-collaboration between technical and non-technical people.

- It’s explainable, transparent, and provable.
- Uses TTT, DSLP, WTS (not NLP or Semantics) to find what you’re looking for, not what it infers.
- Offers pre-built editable taxonomies for the financial and IT domains.
- Works top-down through your corpus at the file level, not the sentence level.
- Generates sortable metadata to summarize textual content in a numerical format.
- Measures color-coded topics, highlights key terms in on-topic files, and filters out irrelevant ones.
- Encapsulates your business language and domain expertise in your software on an ongoing basis.