
Unlocking Value from Unstructured Text
Experts estimate that 90% of digital data generated daily is unstructured. Unlocking value from this overwhelming volume requires surfacing precise, relevant information — fast.
DataScava is an advanced unstructured text data-mining solution that precisely pinpoints high-quality data with user-controlled business and domain language that harnesses your expertise. It evolved from TalentBrowser, where we patented deterministic methods to structure, filter, curate, match, and route nonlinear content — without requiring training data or manual labeling.
Unlike AI tools that rely on probabilities, our proprietary indexer measures and scores the information you care about automatically, generating structured metadata and explainable outputs suitable for audit and governance—working standalone or with other solutions. A completed Qlik Sense integration demonstrates its fit within modern analytics environments.
DataScava can help you:
- Structure, measure, filter, match, route, sort, and rank raw text automatically
- Feed explainable, auditable outputs into AI, LLMs, ML, RPA, BI, Research, and TA use cases and day-to-day operations
- Create domain-specific data pipelines upstream, audit and measure results downstream
- Get structured, high-quality datasets and output you can act on
- Stay in control with results you can see, refine, and trust
How It Works
DataScava applies three complementary methodologies and heuristic techniques that focus on your business language and expertise, not generic language models:
DSIndex | Domain-Specific Language Processing (DSLP)
- Structures and measures user-defined key terms exactly — with no disambiguation
- Generates structured file-level metadata, including corpus-relative percentile rankings, for efficient retrieval and downstream use
- Outputs metadata for use in other solutions and BI tools (Qlik, Tableau, etc.) for visualization and analysis
- Reprocesses automatically when vocabularies are refined in DSTopics or thresholds are adjusted in DSMatch
- Tailors outcomes to your business and domain language instead of generic models
DSTopics | Tailored Topics Taxonomies (TTT)
- Import, build, or select vocabularies and data types that reflect your business and subject matter expertise
- Define and weight domain language for accurate results and continuously refine to adapt to changing needs
- Add, delete, and edit terms on the fly; DSIndex reprocesses and rematches files instantly
- Use taxonomies across multiple domains and contexts to scale without duplication
- I.E., “Covid-19” topic is in a medical taxonomy but not IT. Investment banking topic has “Derivatives,” retail banking has “Checking Accounts”
DSMatch | Weighted Topic Scoring (WTS)
- Categorizes and prioritizes files using user-defined Weighted Topic Score thresholds across must-have, NOT, and nice-to-have Topics
- Refines results through multi-level ranking, filtering, sorting, and routing across matches and topics
- Highlights weighted terms in topic color and displays dual bar charts for full transparency and validation, making gaps and matches obvious
- Continuously processes new files so they are auto-classified into cohesive groups based on user-defined types
- Ensures prioritized outcomes that reflect your rules and defined thresholds
Together, they form a patented approach we call “Profile Matching of Unstructured Documents” — modeled after a contour profile gauge carpentry tool, because DataScava measures language based on your priorities.
Prebuilt Editable Taxonomies
Jump-start your projects with ready-to-use taxonomies for Financial, IT, and Talent domains — fully customizable and expandable. Select, edit, or build on them to reflect your unique expertise.
The DataScava Difference
- Less time, more accuracy – Filters and categorizes automatically, so experts can focus on real business problems instead of tedious labeling
- Precision at scale – Produces explainable, numeric results you can trust across industries and contexts
- Transparency over black-box AI – See and audit exactly why a file matched, with visual highlights and numeric thresholds
- Handles messy data – Irrelevant documents are filtered out automatically
- Scalable and domain-specific – Refine vocabularies, taxonomies, and scoring to meet evolving business needs
- Human in Command – You remain in control, with automation working alongside your expertise.
- Deterministic by design – Unlike NLP/NLU, it doesn’t infer meaning; it measures what you define and presents data in transparent, actionable context

Transparent Results You Can See
Transparency is built into every step of DataScava. The platform provides visual proof of its outputs, so you can trust and act on your data.
File Match
Dual bar charts show how a file scores against required and desired topic thresholds, making matches and gaps immediately visible.
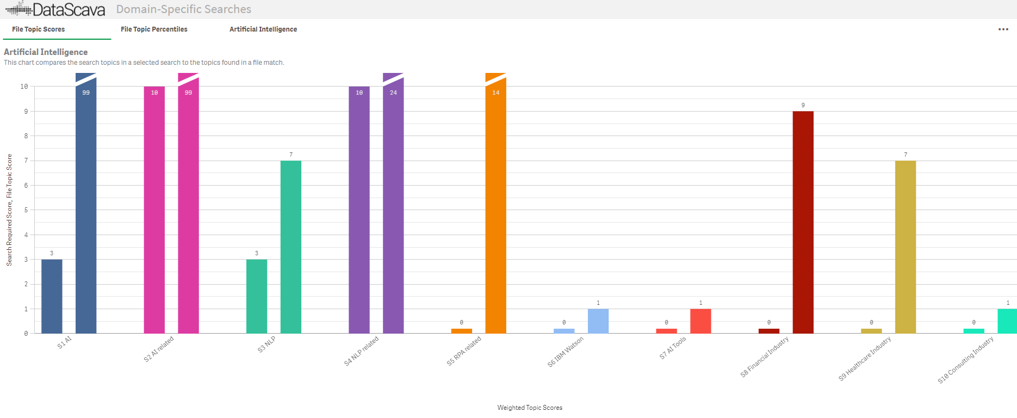
Color-Coded Topic Key Terms
Highlighted and color-coded terms make it clear which terms contributed to topic scores — and which did not.

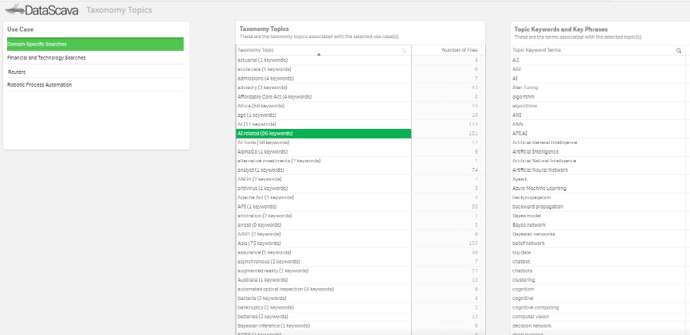
Tailored Topics Taxonomies
Build, import, and refine business-specific taxonomies in real time to reflect your unique language and expertise.
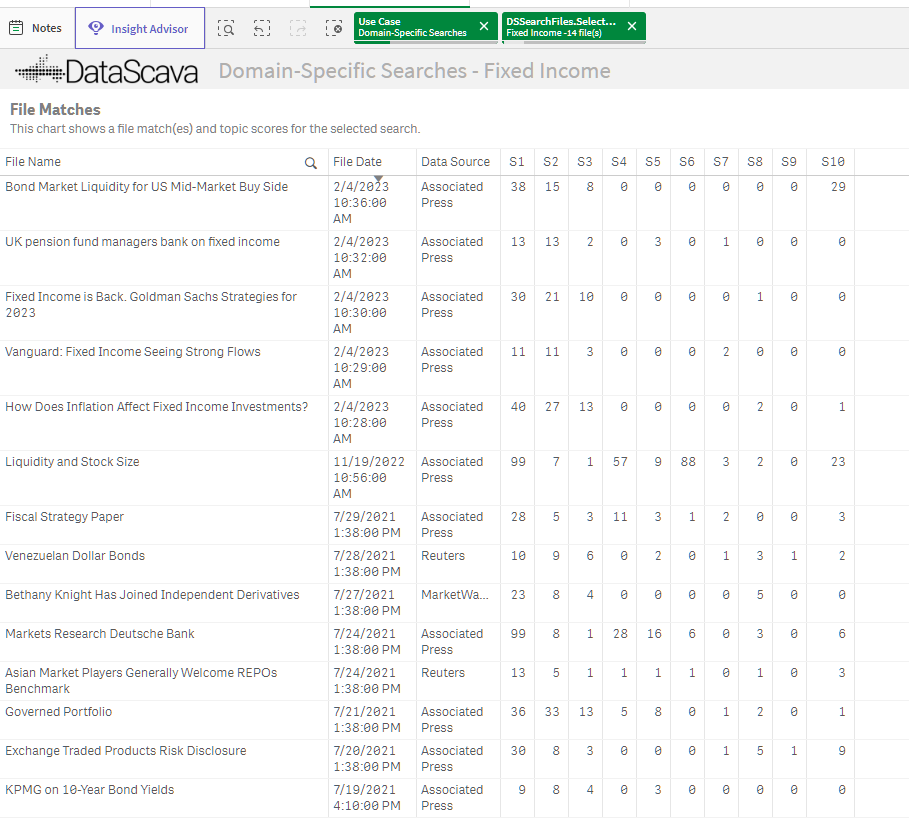
DSMatches Grid
A sortable grid view shows each file name with its numeric topic scores, so you can rank, filter, and multi-sort results by your own priorities.
Why Choose DataScava?
Transparency Over Black-Box AI:
DataScava empowers users to understand and control their data, providing clear explanations for its outputs.
Handles Messy Data:
DataScava classifies, tags, and labels unstructured text without requiring extensive cleansing. Non-relevant documents are ignored after classification.
Human in Command:
Unlike traditional AI that replaces human effort, DataScava enhances it, ensuring users remain in control while benefiting from automation.
Domain-Specific Taxonomies:
Pre-configured taxonomies are available for Financial, Technology, and Talent Analytics domains, with customizable options to suit your unique needs
Integration and Deployment Options
DataScava is available as:
-
A standalone application
-
An embedded solution integrated with your AI, BI, LLM, research, or analytics stack
-
A behind-the-scenes engine driving other platforms or tools
Deployment options include:
-
On-Premises: Reads from your local database and writes scored index metadata back
-
Cloud-Based: Hosted on AWS with indexes stored in a secure private cloud
-
Golang API Integration: Seamlessly retrieves index values and metadata via event-based API calls
An open architecture makes it easy to integrate with other systems using SQL or REST APIs in real-time workflows.