Start with what matters Measure what counts
Patented, transparent, deterministic matching. Pinpoint unstructured
text with business and domain language you define and prioritize.
Structure, measure, weight, filter, curate, and route your messy content before or after other solutions act.
Get the data you need for AI, LLMs, BI, RPA, Research, TA, and BAU.
No training, no black-box guesswork. Just clear, explainable results at scale.
Keep the Human in Command with patented Weighted Topic Scoring and Domain-Specific Language Processing
What a Chief Data Scientist Says About DataScava
“DataScava perfectly complements existing approaches to unlocking the value of unstructured text data – by helping companies to model higher-level intents and purposes behind the labeling and classification of data – by defining the abstract topics and themes that represent their own business and subject matter expertise – and by applying both to big data sets real-time.“
-Scott Spangler, Chief Data Scientist, IBM Distinguished Engineer, Master Inventor in the Watson Innovations Group,
Author of the book Mining the Talk: Unlocking the Business Value in Unstructured Information
Read More
How It Works
Turning noise into signal
DataScava works 24/7 on processing unstructured text with user-controlled language and heuristic techniques. It generates structured metadata from messy, nonlinear content — measuring and surfacing what matters with no training, no guesswork, and total control.

Define. Measure. Match.
A deterministic pipeline for unstructured text
DSTopics
Tailored Topics Taxonomies
(TTT)
Defines and models domain-specific features within heterogeneous text. Import, select, create, and edit specialized taxonomies to incorporate your business language and expertise. TTT ensures precise categorization, offering the customized and flexible vocabulary logic necessary for complex document processing.
Read More
→
DSIndex
Domain-Specific Language Processing
(DSLP)
Using the language of your industry and organization, generates numeric measurements and percentiles of key terms at the file level. Tailored for precision, it identifies user-defined jargon and integrates domain-specific expertise into the language processing pipeline, surfacing the most relevant files from even the largest datasets.
Read More
→
DSMatch
Weighted Topic Scoring
(WTS)
Mines indexed data and categorizes files into cohesive groups based on user-defined Required, Desired, and Not weighted topic score thresholds and types. Results are refined through multi-level ranking and sorting across matches and topics, with color-coded highlighted topic key terms, ensuring prioritized outcomes that reflect your business language and expertise.
Read More
→
Unlock Your Data
What you can count on

DataScava captures the business ontologies that bridge standard data science techniques with the human expertise machines can’t replace — making unstructured data transparent, explainable, and actionable. It doesn’t just structure text — it makes it usable so you can act on it.
- Curate datasets for AI, LLMs, and Machine Learning models
- Feed Business Intelligence and Robotic Process Automation with high-quality, domain-specific outputs
- Route the right content to the right team, system, or workflow
- Enrich Research and Talent Acquisition with transparent, auditable scoring
A Weighted Topic Scoring File Match
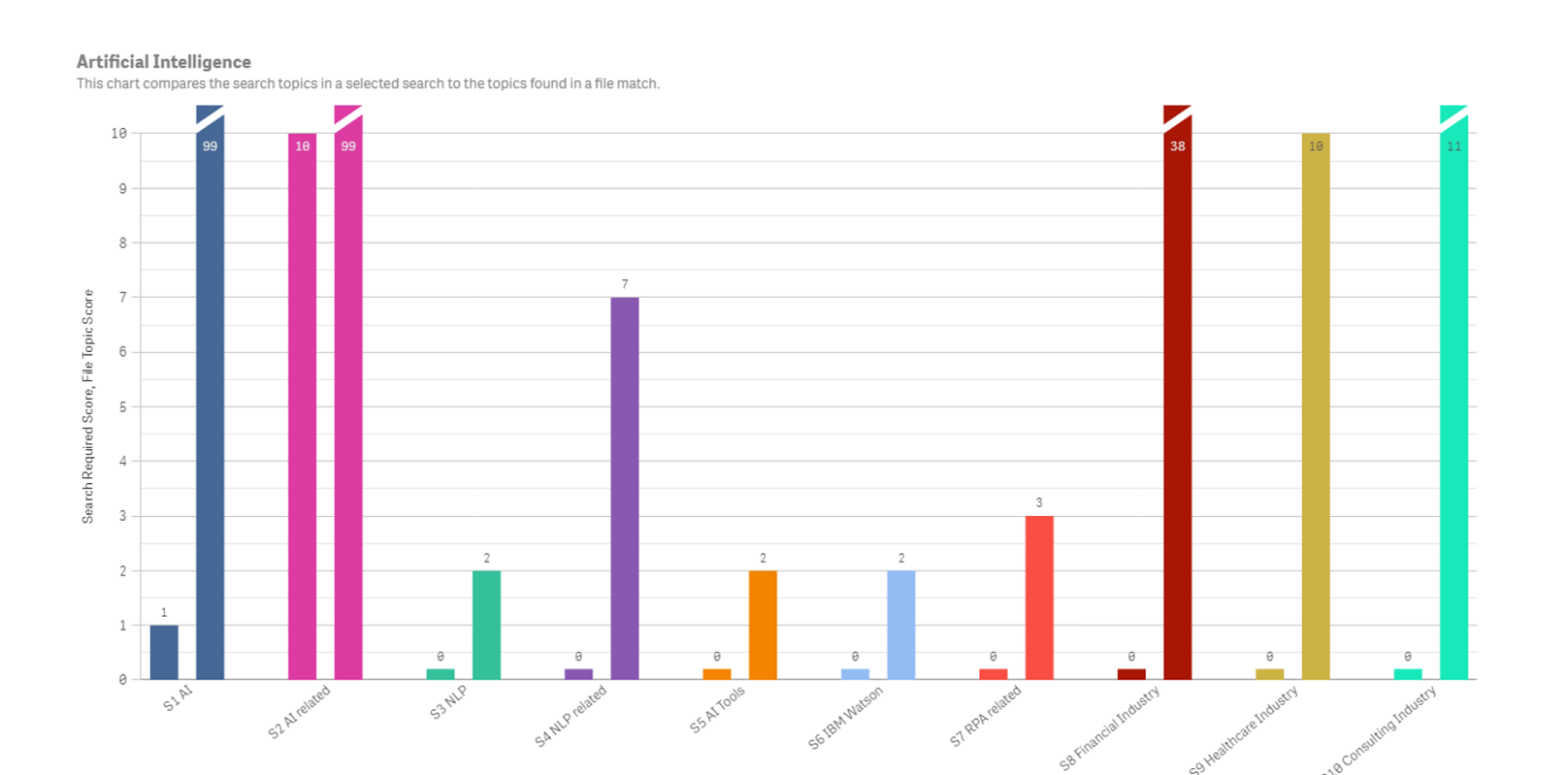
DataScava takes a data-centric approach to business text, using topic models that reflect your industry’s real language. Flexible scoring encodes your organization’s priorities, ensuring processing aligns with how people actually communicate.
With WTS, you assign importance to the terms that matter across must-have, NOT, and nice-to-have Topics. This advanced scoring function lets you cut through noise, surface critical insights, and make better decisions — and only delivers matches that meet all of your defined criteria.
Why DataScava Stands Apart
DataScava fosters collaboration between technical and non-technical people — encapsulating expertise and domain language for ongoing use.

How It Delivers
Proven in practice
Explainable and Transparent
Clear processes ensure you always know what the system does—and why.
———
DSLP-Driven, Not NLP
Delivers exactly what you define, avoiding inferred or ambiguous results.
———
Prebuilt Editable Taxonomies
Ready-to-use for financial, IT, and talent domains—customizable and expandable.
———
File-Level Analysis
Works top-down through your corpus at the file level, not just sentences.
———
Numerical Metadata
Summarizes text into sortable, actionable numeric metrics.
———
Color-Coded Insights
Highlights weighted topic terms in color for instant visibility and validation.
———